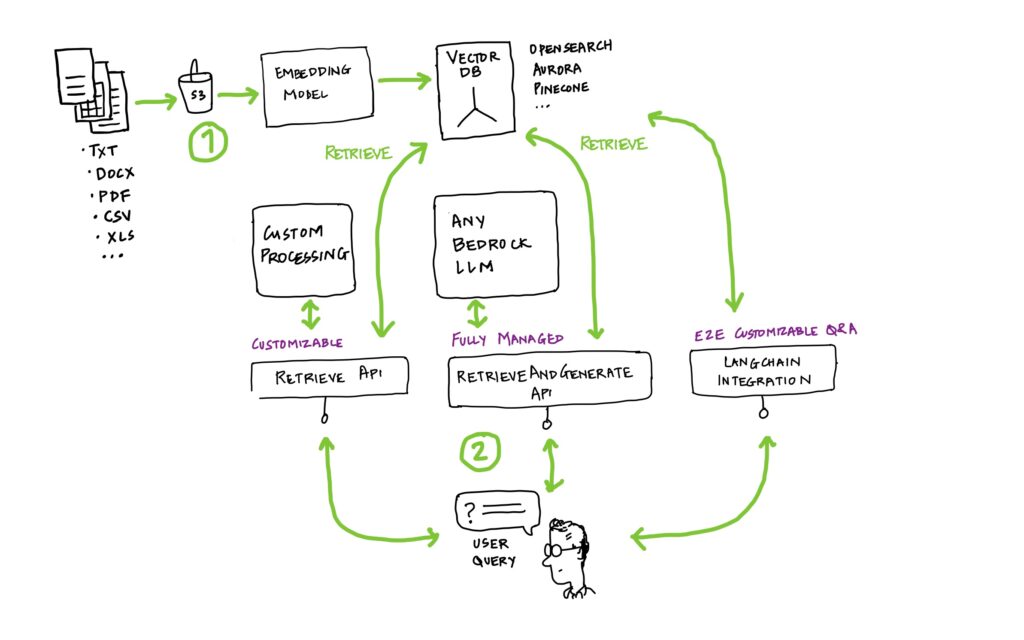
Large language models (LLMs) are amazing but one shortcoming is that they wont be able to answer questions related to your private data. This is where RAG or retrieval-augmented generation comes in. RAG is a technique that lets you use LLMs with your private data.
Dont roll your own RAG
RAG architecture has quite a few moving parts. It involves a ingestion database, vector database, retrieval system, prompt, and finally a generative model. Moreover these need to be orchestrated so that they can ingest new or updated data. Managing these interconnected components adds challenges to the development and deployment process that can slow your team down. Open source libraries can simplify these tasks but risk introducing errors and require constant version updates. Using these libraries still demands substantial coding, determining data chunk sizes, and generating embeddings.
👉 Your team should focus on building your product and not on the undifferentiated heavy lifting behind a RAG process.
Hello BEDROCK KNOWLEDGE BASE
Here is how simple it is to setup a fully managed RAG that is secure, simple and production grade.
1. Create a Knowledge Base
Knowledge Bases for Amazon Bedrock is a serverless approach to building your RAG workflow. It automates synchronisation of your data with the vector database.
Simply point to the location of your data on S3 and Knowledge Base takes care of the entire ingestion process into your vector database including embedding and synchronisation when your data changes. Your data could be in a multitude of formats e.g. txt, csv, xls, doc, pdf etc.
You can simple use the default embedding models and vector database or choose your own.
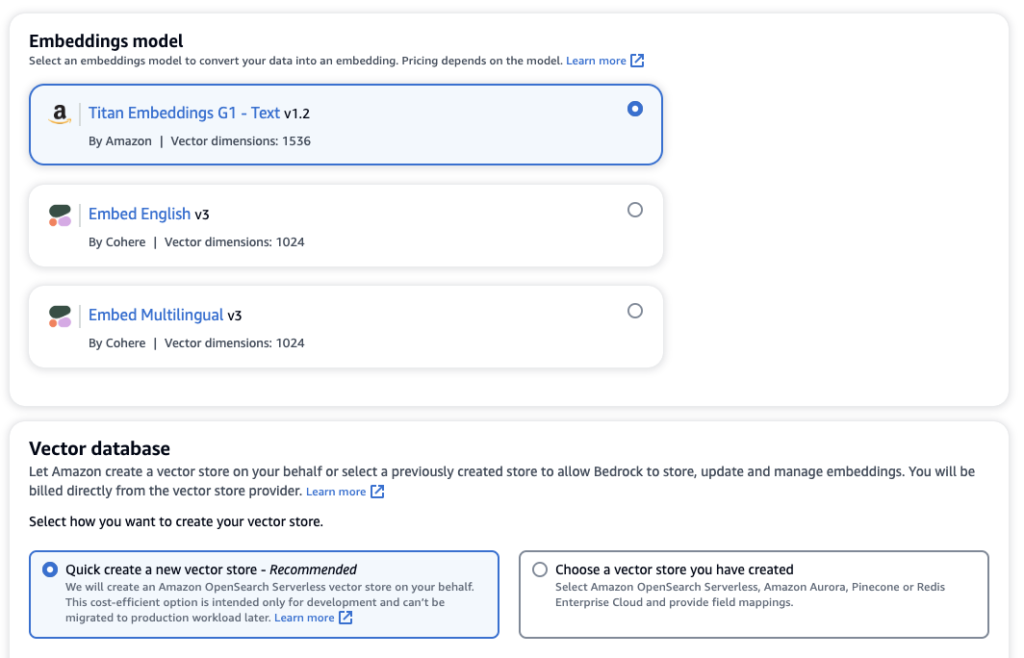
2. Query your knowledge base
Once your data is ingested. You can go ahead and start talking to it. There are different ways to query your data.
USE the AWS Console
The console lets you quickly try both retrieval and generation.
Retrieval
This means finding the correct set of documents based on the user query. Your can try different queries like hybrid search, semantic search or let bedrock choose one for you. More about that in this post.
GEneration
Next is “generation” i.e. taking the search results that you have pulled from the vector database and bundling it as a context together with the user prompt and sending it to an LLM. Choosing a model is just 1-click. e.g. Select Claude and have it generate answers for you. All the plumbing happens instantly behind the scenes and you can focus on getting the best answers from your data.
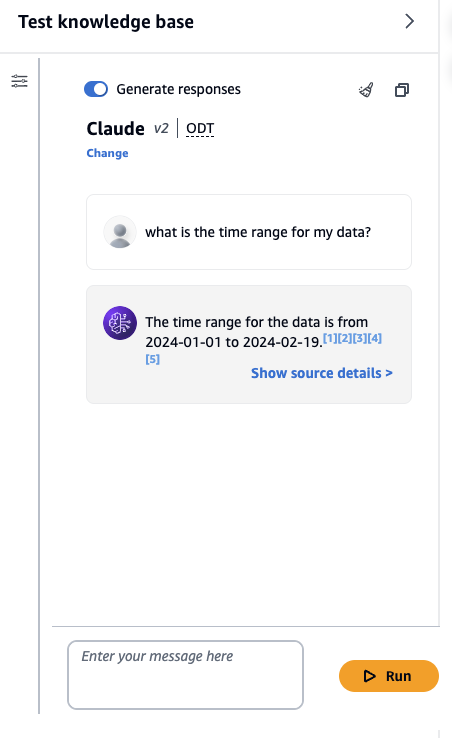
Here is a simple screenshot but it demonstrates the entire RAG workflow.
- Private data was uploaded to s3.
- Data was ingested and embedded into a vector database.
- The vector database prepared a context based on my query.
- Then that context was sent to Claude together with my prompt.
- Claude then generated a response that you see below, moreover it even attached links to my data that helps us trace the answer to the data.
The first step is manual, the rest is entirely managed by Bedrock for you!
Use the SDK
If want to develop and app or talk to your data via a notebook, its easy as well. You just need the latest AWS SDK. e.g. Here are some api options if you use python.
– api: retrieve_and_generate – Retrieve documents and obtains answers directly with the native Bedrock Knowledge Base.
– api: retrieve – Retrieve documents based on your query and then pass it to an LLM of your choice.
build a fully customiSEd solution
If you want to build you own fully customised Q&A application you can integrate bedrock with langchain. Have a look at Langchain integration.
👐
Thats it, it really is that straightforward to put together an LLM with RAG.
🚀 Get Started
👉 For a step by step walkthrough on setting on RAG on bedrock read this blog post.
👉 For a really good look at how to use RAG for drug discovery using Amazon Bedrock, read this blog post.