
SELF-RAG is a method that can make your LLMs more accurate by using self reflection. You can read all about it in this white-paper 👉 Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
TL;DR
The paper addresses the challenge of factual inaccuracies in large language models (LLMs) due to their reliance solely on parametric knowledge. Current Retrieval-Augmented Generation (RAG) methods aid in reducing factual errors but have limitations, such as indiscriminate retrieval of passages and inconsistency in output relevance.
Self-Reflective Retrieval-Augmented Generation (SELF-RAG) enhances LLMs by adaptively retrieving passages and using self-reflection to assess quality of its response.
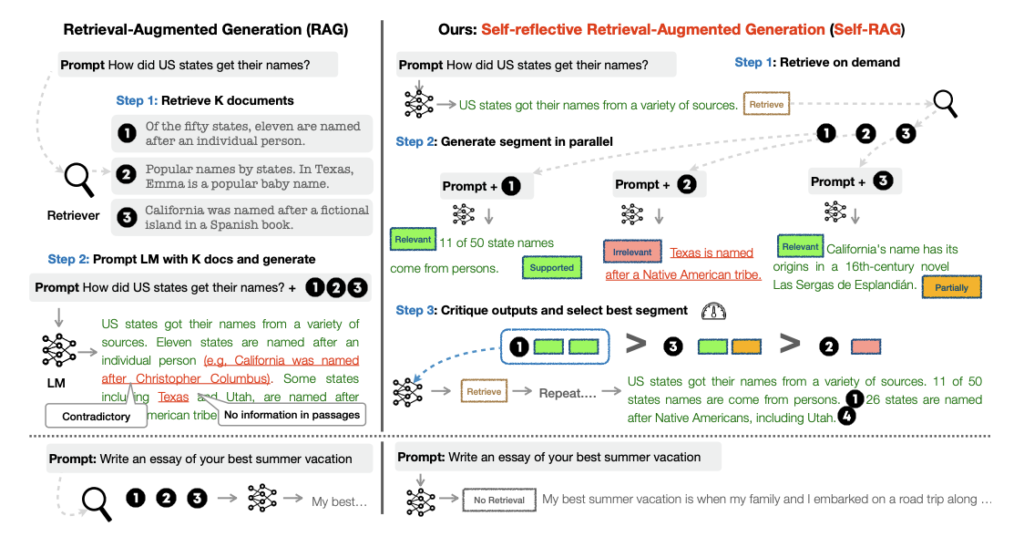
In regular RAG, we retrieve documents regardless if they are necessary or not, in SELF-RAG it is more ‘on-demand’ retrieval.
In simple words, lets imagine a sentence is being generated, here is what the framework does:
a. Retrieval – SELF-RAG evaluates if further generation of text will benefit from retrieval, and if so, generates retrieval tokens and processes retrieved content in parallel.
b. Generate – If retrieval was necessary, the model will generate critique tokens that indicate if the retrieved documents are relevant. If retrieval was not necessary then it will proceed like a normal LLM.
c. Critique – If retrieval was needed, the model evaluates if the retrieved passages support generation and the overall response.
EVALUATION
According to the paper, the SELF-RAG approach demonstrates a significant improvement in performance.
Experiments show that SELFRAG (7B and 13B parameters) significantly outperforms state-of-the-art LLMs and retrieval-augmented models on a diverse set of tasks. Specifically, SELF-RAG outperforms ChatGPT and retrieval-augmented Llama2-chat on Open-domain QA, reasoning and fact verification tasks…
https://arxiv.org/abs/2310.11511
👐
This summary just scratches the surface of SELF-RAG’s potential. Fancy a deep dive, here is the Github repo